If you're giving a presentation, making an argument, or proposing something, the most important thing to keep in mind is: what's the takeaway? It's not sufficient to just lay out information, you also need to provide the conclusion, reaction, or decision that the information implies.
Now, why is this? If you're providing information to someone, surely it's their job to decide how to respond? Perhaps that's true, but in reality, people don't tend to notice, or if they do they don't mind. Even if they disagree with your conclusion, it's much easier to build their response from yours than create one from scratch.
If you're providing information, your optimal strategy is to predigest that information so that your audience has to do less work digesting it themselves. Compared to undigested information, yours will spread further, evoke stronger responses, and be easier to understand.
However, as a consumer of information, this is deeply problematic. Firstly, the choice of predigested conclusion will frame your response, even if it doesn't dictate it. You may agree or disagree, but you're far less likely to find a totally unrelated conclusion or different angle on the idea once you have an existing conclusion to work from.
The second issue is that working out a conclusion for yourself is an important component of understanding. Much the same way that you can memorise the answers to a test, you can agree with a response without really understanding how that response follows from the information. In fact, you may not even realise when it doesn't.
This is particularly troubling in the context of modern journalism and social news, where the line between editorial and reporting is blurry, and the incentive structures of advertising and social media encourage making content as easy to digest and share as possible. You will very rarely find viral content that doesn't also tell you how to react to that content.
Even if the content itself doesn't contain a predigested reaction, the comments are a selection of ready-made reactions for you to choose from. It's a common pattern on popular social news sites to read the article, then read the comments, then decide what you think. But by that point it's more a matter of choosing who you agree with than forming your own opinion.
In conclusion, it may be better to stop reading before you reach the part where an author goes from providing information or making arguments into telling you how to respond. If the content is designed to make that impossible, perhaps it's not worth reading at all. And, furthermore, Carthage must be destroyed.
What do rationalists, atheists, egalitarians and polyamorists have in common? I mean, other than often ending up at the same parties?
These are all identities that come from not believing in something. For polyamorists, it's exclusivity in relationships. For egalitarians, it's differences in value between people. For atheists, it's gods. And for rationalists, it's anything that doesn't change your predictions.
However, the negative is a slippery beast. You could say that a religious person's identity also comes from not believing in something: atheism! So to describe this idea in more precise terms, let's return to the concept of additive and subtractive: you can call something additive if it tries to build from nothing to get to the desired result, and subtractive if it tries to start with some existing thing and cut away at it until the desired result is reached.
To see these different approaches in action with respect to belief, consider a scientific vs religious approach to truth. Science begins with a base of small, empirical truths obtained from observation, and attempts to build from that base to big truths about the universe as a whole. Conversely, religion begins with a big truth about the universe – there's a god and he does everything – and attempts to cut that exhaustive belief down into small everyday truths. If you ask why stars explode, a scientist might say "I don't know", while a religious person would be more likely to say say "I know God did it, but I don't know why".
So to resolve that negative from earlier, "not believing in something" in this case means not accepting some particular subtractive truth you are expected to accept as a given and work backwards from. Instead, you attempt to start from nothing and build additively to that truth. And, in the case of these various non-beliefs, find you can't do it.
What god would develop in a society that never had a god? What hierarchy of human life? What sexual mores? The answers would depend mostly on the popular subtractive truths of the time. Not so with additive truths. In Ricky Gervais's words, if all the books were destroyed, a thousand years from now we'd have different holy books but the same science books.
Perhaps this outlook could be considered a feature of rationality, skepticism or the scientific method, but I think of it as the ur-discipline, the belief behind these various non-belief systems. Don't accept truths that you can't build to additively. Take as little as possible for granted. It is not possible to have a belief system without axioms, but treat all axioms with the utmost suspicion. If they cannot be removed, they should at least make the most modest claims possible.
There is something deeply appealing to me about this way of thinking. It's a kind of intellectual asceticism. A cosmic humbleness. Rather than treating the truth as a big book of mysteries given to us to decipher, we treat it as a structure of our own creation; small at the base, but expanding ever outward into the darkness.
This is a writeup for my work on Mind Music, a presentation at the inaugural Spotify Talks Australia. The talk was presented by Professor Peter Keller of the MARCS institute at Western Sydney University, organised by my friend and previous collaborator Peter Simpson-Young, and included a live visualisation/sonification of brain activity I built based on my prior Project Brain work.
The visualisation/sonification had two parts: one that would show general brain activity, and one that would show the brain responding specifically to music, synchronising with the beat in a process known as neural entrainment, sometimes more specifically called steady-state audio evoked potential (SSAEP), or audio steady state response (ASSR). Although the broad strokes of the data processing were similar to Project Brain this new entrainment demonstration had some unique and challenging features.
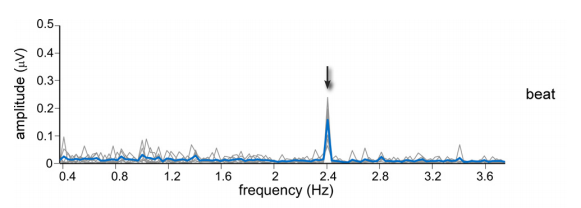
We were attempting to reproduce a particular scientific result from Tagging the Neuronal Entrainment to Beat and Meter by Sylvie Nozaradan et al (pictured). Rather than the previous broad-spectrum visualisation, the goal here was to look for a rhythmic brain response that mirrors the BPM of a particular song. That is, if we're listening to 144 beats per minute, that's 2.4 beats per second, so we should find increased activity at 2.4Hz.
The original paper used data from multiple phase-locked trials averaged together. That is, the same experiment was tried multiple times, but crucially the timing was identical each time. You can imagine the equivalent situation with music: if you play ten copies of the same drum beat at the same time, you get a really loud drum beat; if you play them at different times, you just get an unintelligible jumble.
With our demo being live, we couldn't stop and start the recording. Instead, I attempted to come up with a live equivalent of this averaging process, which I called "epoch rolling average", or ERA. An ERA splits the data up into chunks of a certain size and averages them together, with the oldest chunks being discarded as new ones come in. The key part of this is that if the chunk size is a multiple of the frequency in question, then the chunks will end up synchronised with each other without requiring manual synchronisation.
Another difficulty is that the Fast Fourier Transform, used in both the scientific paper and my original visualisation, has some restrictions that made it tricky to work with. It tells you all the different frequencies that make up a signal, but the frequencies are grouped into bins, whose precision depends on how long you collect data for. More data means more bins and thus more precision, but also more latency between when you start collecting data and when you see the output.
Complicating this is that which frequency each bin is centred around is also related to how much data you use. We could pick data sizes so that our frequency would be in the centre of a bin, but the "fast" in "Fast Fourier Transform" requires that we use a a power of 2. We could make up for that by increasing the size until it got precise enough that it was really close, but that would, again, take longer and make it less real-time.
To get around this, I turned to a different kind of Fourier transform technique called the Goertzel algorithm. This is much less efficient than the FFT per frequency, but also allows you to pull out a single frequency at a time. Since in this case we only wanted a few, that meant I could ditch the power-of-2 restriction and make the frequency we wanted fall right in the centre of a bin.
Beyond the technological challenges, there were some interesting new parts to the visualisation. Most of the work for this was done in Unity by Alex Lemon at Rh7thm. I provided a specific data feed for the visualisation that included the colours, animation speed, amplitude and phase for each brain segment, and then he used those parameters to animate a 3d brain model. There was a lot of fine tuning involved, but the end result ended up looking really nice.
As for the sonification, a lot of that was based on my previous pentatonic mapping, but with a lot more tuning to make it sound less shrill and more chill. This pentatonic sonification was used for the first part of the presentation, where we talked about general brain activity, but we also wanted something less ethereal and more rhythmic for the beat detection demonstration.
What I ended up doing was a low bassy frequency with a kind of tremolo and wobble filter on top of it. To make that work properly, I needed to make sure the bass synced with the music, so I had to add some code to cue the music from within the sonification, and only on an even multiple of the beat. I used Web Audio for all of this and, although it got a bit tricky to keep everything orderly with so many components, the flexibility it gave me was totally worth it.
The goal for this ended up being an interesting mix of science and theatre; on the one hand, we were attempting to build on a genuine scientific discovery in an interesting and novel way. On the other, we were there in the spirit of showmanship, trying to make an entertaining audiovisual complement to Professor Keller's presentation.
So how well did we succeed? It definitely wouldn't rise to the level of real science, not least of which because rather than starting with "how do we test a hypothesis?" we were starting with "how do we make something that looks good?" The way the visualisation was designed and tuned basically guaranteed that something would happen, though it would be more intense the better the beat was detected. The signal from our consumer-grade EEG was pretty noisy, and it could be that what we visualised in the end was as much noise as it was neural entrainment. On the other hand, all of the processing we did was legitimate, just not provably so.
But I would say its value as an entertaining and informative visualisation was undeniable. The crowd had a good time, the presentation went smoothly, and the technology all survived a live stage demonstration, despite some terrifying last-minute wireless issues. I had a lot of backup options ready to go in case something failed and, even though I didn't need to use them, having them there really took the edge off the live stage performance.
I recently watched Alan Kay's How to Invent the Future (and part 2), and one thing I thought was particularly interesting was his idea of trying to invent the future from the future. That is to say, rather than extrapolating from now to the next 10 years, extrapolate to the next 30 years and then work backwards. That way you're finding an incremental path to a big vision, as opposed to ending up with a small and incrementalist vision.
In that spirit, I thought I'd come up with some 30-year predictions:
Memetics is redeveloped as a practical discipline, becoming the primary driver behind development of entertainment (games, social media) and social influence (politics, PR). Dopamine-farm distraction technology becomes worryingly effective. Deep questions begin to emerge about who is actually making decisions when we're all so easily manipulated on such a large scale. Anti-memetics and non-democratic forms of government become serious areas of consideration.
Software development splits into distinct disciplines, both vertically (architects vs engineers vs builders vs technicians) in its current general-purpose focus and horizontally away from general-purpose towards different special-purpose forms for different domains. This isn't so much DSLs as distinct paradigms like Excel formulas, Labview or MaxMSP. Most people program computers if you consider a wider definition that includes this "soft" programming.
Elimination of all passive media, ie all documents/images/movies etc become executables containing both the data and the code to interpret them. This is partly for DRM and partly to enable new interactive forms. Sandboxing and trust models replace Turing-restriction for software safety. (You can already see this happening on web and mobile). Most media becomes dynamic or interactive in some way, even if the main experience is still non-interactive, eg movies with an embedded chat box.
Human interaction becomes almost entirely machine-mediated, leading to people accustomed to complete control over their social interactions. Huge industry of asymmetric transactional relationships (livestreamers, social media personalities, personal services etc) with defined parameters. This leads to a healthy but small market of countercultural "talk to someone you might not like without being able to immediately get rid of them" services and quaint local-community-based interaction. Most people will be happy enough only interacting with others in controlled circumstances.
Semi-autonomous companies dominate the market as machine learning algorithms demonstrably trounce human judgement in investment, management, and executive-level strategy. People are still involved to do work that is not currently automatable, but that field shrinks from the top as well as the bottom. There is a commensurate increase in value for creativity, which continues to elude AI. Most people are not employed, either spending their time on human-centric creative pursuits like art or sunk deep in a well of machine-optimised distraction.
I've been thinking a bit about this month's Conventional Wisdom. What's the point of it? I mean, maybe if I've forgotten about something for long enough it should stay dead.
But the problem is, while I'm sure some things do just drop completely out of your memory, my experience is that they're not really forgotten; little bits of them hang around. The ghosts of discarded-but-not-quite-abandoned projects come back to haunt you when you're out for a walk, trying to sleep, or in the shower thinking about something else.
In that sense, then, better late than never is really an extension of statelessness; rather than having all your projects in some indeterminate state, the goal is to drive them to completion or destruction. Either you're doing them or not doing them, but maybe kinda doing them is an extra load on your working memory that you don't need.
To that end, I've started doing something substantially out of my comfort zone: closing windows. By way of explaining how much of a change this is, I usually have probably a hundred tabs and windows open spread across 10 virtual desktops. I do this not because I'm using all those windows, but because it's easier if I want to pick up where I left off on a project.
But that, too, is yet more state. Every Chrome window full of tabs I intend to read later is an extra burden I have to carry around. Every Sublime Text window full of notes I should probably file away is a drain, not just on my computer's memory but my own.
Worst of all, this has a very obvious effect on my focus. When I start working on something, I don't have to just find the windows that are relevant to that project, I also have to ignore all the ones that aren't. At the critical and vulnerable time between tasks, it's so easy to see some stray email or article I've been saving up and get distracted.
Anyway, no more. I've realised that rather than starting with lots of junk and subtracting my way to what I want, I should instead start with nothing and add to reach what I want. In other words, no old browser windows. In fact, no old windows of any kind. I want to sit at my computer and see an empty screen waiting for me to fill it with something useful. A blank slate.