Today I did a fun little DIY project as a gift for a friend. I bought a baby Groot bobble head, cut its head open and filled it with dirt and chia seeds. The ultimate outcome should be a Groot chia pet, but I'll have to wait a couple weeks to see if it turns out.
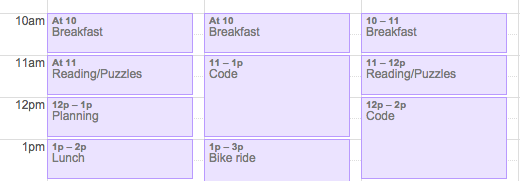
One technique I've found pretty useful for keeping my days on track is using a timetable. That is, dividing my entire day up into calendar entries describing what I should be doing at any given moment. I haven't really seen much of the humble timetable since I left university, but I think there are a few qualities that make it useful for creative work.
A timetable might sound overbearing, but it's important to remember that, like any measurement or management tool, it's only as draconian as its consequences. In my use, I don't find much benefit in getting upset when something happens and throws the timetable out. Rather, I adjust the timetable so that it makes sense for the rest of the day and use it as an opportunity to think about whether that adjustment was a good thing.
In fact, I'd say that's the main benefit of having a timetable. Without one, your day can slip arbitrarily and you don't even notice. Someone calls and you lose fifteen minutes. You get sidetracked by some interesting website and half an hour's gone. Suddenly the day's over and you're surprised to discover you've done half as much as you expected. With one, you not only notice the slippage, you can correct it by making changes to the rest of the day.
The other main benefit is that it forces you to put a bit more effort into planning your day. My default plan looks roughly like "do things until I'm done", which has the benefit of simplicity but not much else. Explicitly blocking it out makes it obvious when there aren't enough hours to do everything you were planning, particularly on days where other commitments intrude. It also makes it much clear when you're not leaving yourself enough time for breaks, exercise or fun.
Basically the only downside is having to remember to put aside time to do it, which is the kind of problem you can solve with the judicious application of even more timetabling.
I was at a Less Wrong meetup the other day and the conversation got around to self-measurement, as it often does. It reminded me of this app idea I've had floating around for a while.
I've tried a few different methods for self measurement, but none of them have suited me particularly well. I mainly use spreadsheets, which are great and very flexible but hard to stay on top of. If I'm particularly busy I tend to forget about them, which is sadly the exact time when I'd most like to have good information.
I've also dabbled with automatic window tracking software like RescueTime and Time Sink but it's never really stuck. Time Sink is basically unmaintained now and didn't give me very useful information. RescueTime was great but I find the idea of every activity on my computer being stored in one NSA-friendly database supremely creepy.
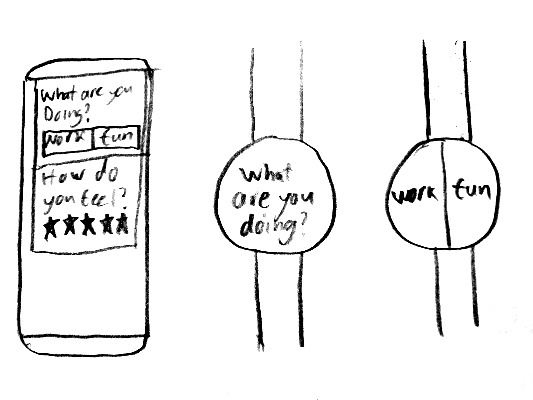
One third way I've heard about is random sampling. Instead of having to actively manage your measurements or build them into a monitoring system, you just get a prompt at random times asking you quick questions. Over time, your responses will form a complete picture of what you want to know.
Unfortunately, there don't seem to be any good solutions for this at the moment. Most of what's out there seems to focus specifically on one type of question, either mood or "what are you doing now?", but I'd like to ask custom questions. There an iOS app called Reporter that seems pretty nice, but I'd really like something for Android. In particular, something that integrates with Android Wear would be super cool.
In my ideal world, someone else would build that for me, but I suspect I might end up doing it myself. Unfortunately, it'll still be pretty tricky to track my time while doing it.
I've recently been working on yet another distributed system, and I noticed a pattern that I've seen sometimes but that I wish I could see more of. I think it provides a useful lens for thinking about and designing distributed systems.
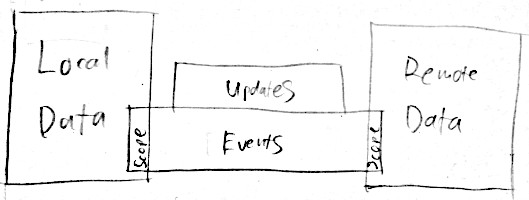
To start with, you have local data and remote data. You address data using a scope, which is some way of addressing that data. Think URLs, database queries, document ids, that kind of thing.
On top of that, you have events. These are messages attached to a particular scope that you access using a pub/sub pattern.
Lastly, you have updates that are implemented in terms of events. That is to say, updates are a special kind of event to synchronise the data associated with that scope.
Here are some varying levels of this pattern in real systems:
IRC
Channels are scopes. IRC protocol messages are events. JOIN/PART/NAMES are update events to synchronise user lists. TOPIC/MODE synchronise other channel state.
CouchDB
Database names and document ids or view functions are scopes. Replication (the _changes feed) implements update events. However, no other events are possible so there's no way to send messages to other people watching the same document.
RabbitMQ
Queues and topics are scopes. Events are implemented as publish/subscribe. However, there's no notion of persistent data attached to the scope.
Redis
Database numbers and keys are scopes. PUBLISH/SUBSCRIBE commands implement events, but they are not filtered by scope. The various update commands are not implemented as events, so there's no way to watch for database changes.
HTTP/Web
URLs are scopes. You can use server-sent events or websockets to implement events, but they're not scoped and not pub/sub. There's also no connection between HTTP documents and those streams - they accept different urls and you have to manage that mapping manually.
Ultimately, most things I work on that don't implement this pattern end up needing it to be reimplemented in some way, either by implementing events on top of the database (as in Couch), building your own mapping between events and data (as in Redis), or just doing whatever and hoping it works out (as in the web)
There are a lot of different ideas that I like, but one particular theme seems to reappear time and time again. I've tried to put it into words a few times, and this is the closest I've come: it's about building a universe from the inside.
When you work with a system enough, you learn and internalise its rules and resources. Maybe the rules of physics, or the tools of Photoshop, or the irrefutable tao of Rails. You learn how to combine resources and manipulate rules to make and do whatever you want. Eventually you become so familiar with that system that it becomes second nature. You no longer think "I'm going to use Photoshop to resize this image"; that would be like saying "I'm going to use physics to go to the park". You just resize the image. You live in the universe of Photoshop as much as you live in the physical universe, and you're building things using the rules of that universe.
More recently, one of those things you can build is a new universe, with its very own set of rules. Of course, societies, languages, games and so on have existed for ages, but they're all built from people and behaviour and tend to be hard to design. But with a computer you can build a universe easily, a consistent universe that follows the rules you decide on.
But when we create a computer program we have to step outside it, and build our amazing new universe while living in the drab universe of squiggles in a code editor. But what if it didn't have to be that way? What if you could create a universe-creating universe where the tools you use to build it aren't accessed from the outside, but from the inside?

{kind=link}